
TMQL Use Cases (editors' draft)
| Title: | Topic Map Query Language, Use Cases |
| Source: | Lars Marius Garshol, Robert Barta, JTC1/SC34 |
| Project: | ISO 18048 |
| Project editors: | Robert Barta, Lars Marius Garshol |
| Status: | Technical document |
| Action: | For review and comment |
| Date: | 2003-12-04 |
| Summary: | |
| Distribution: | SC34 and Liaisons |
| Refer to: | |
| Supercedes: | |
| Reply to: | Dr. James David Mason (ISO/IEC JTC1/SC34 Chairman) Y-12 National Security Complex Information Technology Services Bldg. 9113 M.S. 8208 Oak Ridge, TN 37831-8208 U.S.A. Telephone: +1 865 574-6973 Facsimile: +1 865 574-1896 E-mail: mailto:mxm@y12.doe.gov http://www.y12.doe.gov/sgml/sc34/sc34oldhome.htm Mrs. Sara Desautels, ISO/IEC JTC 1/SC 34 Secretariat American National Standards Institute 25 West 43rd Street New York, NY 10036 Tel: +1 212 642-4937 Fax: +1 212 840-2298 E-mail: sdesaute@ansi.org |
This document is part of the effort to define a standard query language for Topic Maps (TMQL, ISO18048) and as such describes possible use scenarios from both, an application oriented view, but also more detailed in terms of retrieved topic map content. These use cases are intended to support the evaluation process for individual TMQL proposals.
1 Status of this Document
2 Introduction
3 Application Scenarios
3.1 Knowledge Web Sites
3.2 Web Portals
3.3 Content Management (Horizontal and Vertical Markets)
3.4 Enterprise Information Integration
3.5 High-Integrity Systems
3.6 Meta-Data Syndication
3.7 Knowledge Management
3.8 Intangible Asset Management
4 Application Use Cases
4.1 Photo Meta-Data
4.2 Visualisation of Topic Map Data
4.3 Topic Map Introspection
5 Use Case: Literature References
5.1 Problem Domain
5.1.1 Test Data
5.1.2 Assumptions
5.2 Queries with List Output
5.2.1 Conventions for the Sample Output
5.2.2 Individual Queries
5.3 Queries with XML Output
5.4 Queries with Topic Map Output
6 Simple Retrievals
This document is an working draft as commissioned according to [N0423] to collect potential use cases and usage scenarios for a Topic Map Query Language [TMQL]. At this stage only read-only retrieval is considered. Later versions of this document may also cover use cases for updating Topic Map based data.
This document is for review for SC34WG3 members and they are invited to feedback corrections and also comment on the general structure and statement of the document. It should be seen in the context of [tmql-req].
The current document has been made as a best effort to incorporate the individual contributions and the comments made in the Montreal Meeting Report [N0439]. The editors seek confirmation that the comments and suggestions are addressed to the satisfaction of WG3.
Comments can be addressed directly to
the authors, on the IRC channel #topicmaps@irc.freenode.net or via the
official SC34 mailing
list.
See the C Change Log for changes.
Topic maps have a particular structure as defined by [tmdm] and more abstractedly by [RM]. In principle it would be possible - and it has been done - to model the content via a relational data model or - using [XTM] as one possible representation - storing it into an XML (enabled) data store.
For scalability reasons most TM storage solutions tend to build their own dedicated data models and access technologies. From this point on programming interfaces allow application developers to access part of the map, being for reading or writing. In this sense the abstract model defined by TMDM [TMDM] may play a similar role as [DOM] for XML based data, at least in the short term. For reasons of minimality, data models such as TMDM have to be limited in the way how particular TM content is identified in a map.
A Topic Map Query Language may cut down development costs for particular classes of applications. The language would allow to phrase more global queries viewing the topic map content as a whole and not just as a collection of topics and associations. Additionally such a language could also facilitate the generation of output in formats like XML directly in order to minimize the necessary interaction between the application and the query infrastructure.
The following application scenarios and use cases are designed to illustrate the use of a hyperthetical Topic Map query language. They all assume that TM content is stored in an appropriate backend and is retrieved using the query language in a similar way how [SQL] is used for relational data stores. It is also assumed that TMQL can generate output in form of list structures, tree-structured like XML or even complete topic maps.
We will first attempt a high-level characterisation of possible usage scenarios for Topic Map technology in general (section 3 Application Scenarios), but particularly focus on the deployment of a query language. We use these scenario descriptions to cover whole classes of applications. In section 4 Application Use Cases we will narrow down on a few particular applications and loosely define some sample queries which may be typical.
The following section (5 Use Case: Literature References) then singles out one particular application, that of managing literature references with Topic Maps. In a rather trivial, restricted scenario we define first a small test database which we use to define detailed queries with their expected outcomes.
To complete the whole range of use scenarios - from the rather high-level deployment options to concrete queries - the last section (6 Simple Retrievals) then lists rather generic, isolated queries. These focus mainly on specific Topic Map components and simply select parts of a map.
This section provides some high-level descriptions of possible usage scenarios for TMQL. While there may be similarities between them, these applications have been collected to demonstrate the range of TMQL applicability in general.
Such web sites simply host content about a particular organisation, product or theme. Here we do not distinguish between intranet sites which more concentrate on staff information and services and those which address a wider audience. In case of an intranet the knowledge may constitute corporate memory, the agenda of public web site is usually more educational or promotional.
Many professional web sites nowadays master the content out of a content back-end, be it a relational database or some other data store. Which data store technology to choose largely depends on the nature of the content. As long as the content can be disciplined into relational data models, conventional relational databases offer sufficient management facilities to insert and retrieve content fragments. To allow a maximum of content reuse and management, most sites will also attach content management systems.
Once the content becomes more irregular, (native or hybrid) XML databases provide some leeway in terms of storage flexibility. Applications, though, have to interpret XML content to a certain extent to be able to display the relevant parts to a user.
Web sites offering, say, complex educational material do not fall into above categories; the content is neither tabular nor tree-like in nature. Instead, Topic Map back-ends may carry part of the relevant content.
Except for statically prepared web content, all these sites will have to use either one of the numerous scripting technologies or a web application infrastructure to pull content from the back-end and to regenerate it into a format which end user devices, such as browsers, can render.
In case of server-side technologies a query formulated in TMQL will be used to identify relevant content fragments within a topic map instance. The rest of the application will insert the content into templates; this end result will then be sent to the client (see appendix B for a list of detailed queries for content retrieval). In this context application servers so perform typical middle-ware tasks and host the application itself. Also in such scenarios a TMQL query engine can be used to select Topic Map content before it is prepared for output.
A special case are XML applications servers. According to their operational model it is not a program which carries the control-flow to approach the data back-ends at the appropriate times. Instead, XML documents are processed and interpreted. If special XML tags are detected by the XML application processor, then libraries - provided by the application engineer - will be invoked. These [taglibs] will create XML fragments which are inserted as part of the overall output. How much of the production of the XML structure is done by the application or can be done by the TMQL query processor may decide on the ease of use and the performance of the overall system.
In any case XML application servers can then deliver content which can be further transformed into HTML, SVG or other formats.
Web portals differ from web sites in that they cover a larger theme presented for different clientels. An example would be a health portal; in that doctors, nurses, hospital management, government, insurances, and, of course patients will have different views onto the focal theme.
The challenge for the portal maintainer is (a) to capture an sufficiently rich content for all the clients to keep them interested in the portal to such an extent that they also are motivated to contribute content. The portal (b) also has to syndicate the generated content between various user groups and third-parties.
On a knowledge engineering level every user group can be defined via the concepts they are mainly interested in. Patients might be mainly concerned about services, doctors about liabilities in particular situations, hospitals about cost management. The portal thus will (c) have to define ontologies for every such clientel.
All these ontologies, of course, will have to coexist in the sense that they are compatible with each other. Moreover, the portal maintainer will have to define mappings between content adhering to different ontologies. If content is generated by one user clientel then this content follows their prevailing ontology. To be useful for another user groups the content has to be mapped into a different ontology. A Topic Map query language might be of help to automate the task to create a collaborative knowledge base.
Classical document management focuses on the separation of content and layout, but also on managing considerable amounts of documents.
Topic Maps can be used to store document meta-data in a rather flexible way. This information usually will contain rather generic properties like authorship, creation and modification dates. The structure of these attributes have been in standardisation for some time [DC]. This enables software vendors to model them either in a conventional database or in a Topic Map infrastructure.
In many cases, though, rather organisation or business process specific information will have to be added. Governmental organisations will treat documents containing legal texts quite differently than a print publisher will manage customer PDF data or a marketing firm does with Quark Express templates.
Software vendors which create solutions for vertical markets may not only define ontologies to specify what kind of meta-data can be stored; they also will build applications which can answer specific queries such as "when was this legal text first discussed in the parliament?" or "which set of PDF documents was printed in-house with a particular machine in May?" or "in what marketing campaign was a particular Quark Express template not used?".
Enterprise application integration is a term for efforts to connect various separate applications within an information environment. Depending on the prevailing definition enterprise information integration specifically tries to consolidate diverse data sources in to one coherent whole.
XML technologies were of tremendous help in this area and facilitated to reduce eventually the number of different applications and services corporations. Still, when it comes to integrate the back-end data sources a rather flexible data model is necessary. One option - of course - is to use the Topic Maps paradigm.
Unfortunately, in real-life situations it cannot be easily achieved to simply recombine all existing data into one database. This usually has political, commercial but also technical reasons. Instead, Topic Map technology can be used to provide this integration virtually by mapping the individual data resources transparently into a topic map framework. Every such resource then is represented by a /immaterialized topic map/, i.e. a map which only exists virtually for the applications which use the Topic Map access. Internally every access to the topic map is translated into an access to the back-end store, be it a relational database using SQL or a hierarchically organised LDAP database. A TMQL thus provides a homogenuous view to all applications above the Topic Map blanket. Various drivers for different back-ends will provide a transparent translation in both directions.
In a corporate scenario it is normally achievable that the individual immaterialized maps all use the same set of subject indicators. Given that, a standard topic map merge will result in a consolidated view. Otherwise, the merging has to be done according to application specific rules, as for example based on persons' email addresses. In this process a query language may provide the necessary means to generate a semantically consolidated map.
High-Integrity systems not only try to consolidate the information landscape of an organisation or a complex machinery; they also use business and mission aware knowledge systems to improve the human-machine interaction. Especially in mission-critical system involving considerable assets and/or human life this should facilitate that operators make as little mistakes as possible.
As such operators have to make decisions in different situations: tests during normal operation, controlled upgrades of sub-systems, be they hardware or software related and, of course, decisions in abnormal situations to bring the system to a normative state.
Topic Maps can play a role in such as system as link between the documentation management system, the process-aware knowledge base and the physical state of the system. Depending on the intent of the operator, the operational parameters of the application and the current system configuration, the user interface application would use a Topic Map query to retrieve the appropriate documentation.
As such the Topic Map is used as a sophisticated document index holding the knowledge which part of a document is relevant to the given context and which part of the knowledge base is to be consulted.
A content syndicate plays the man-in-the-middle between content producers and consumers. Its business model is to consolidate the incoming (upstream) content technically and content-wise and to deliver content downstream to portals or individuals.
If the content is representable in XML then the whole arsenal of XML processing and transformation techniques can be used to achieve the above goal. For meta-data Topic Maps can be used, but these need a separate set of manipulation technologies.
To illustrate this, assume that a content provider observes the global market of watches. In a contractual relationship with the syndicate he reports on new watch models and price changes of models on the market. Every now and then, new content following the above ontology will enter the syndicate.
Before the syndicate will send this information to its subscribers it may first consider of adding value to this information: Not everyone subscribed will be an expert in this area, so background information about the company producing the model can be merged into the content. This can be done using a query against a knowledge base which has been acquired background information about the watch market. The query would extract company information and would merge this query result into the original message.
The syndicate may also reduce content if it is not deemed relevant to particular subscribers. End consumers might probably not be interested in details about the manufacturing process of that watch model. On the other hand this might be important for a merchant as this may influence shipping decisions. Again, a query can be used to achieve this kind of filtering: for every user class - maybe even for every user - there exists such a query. The content pushed against this query will cause the query processor to only pass through information according to the query.
Finally, the content will have to be brought into a form where it can be delivered downstream. In case of end users this might be text in email or SMS messages, or also HTML for web pages to be picked up by an private subscriber. Here the query language may be directly used to create documents in these formats. A query will simply walk over the message content and will output SMS, XML or HTML content.
For a portal subscriber the topic map might be serialised as it is and shipped as an XTM document. Depending on the agreed service level, though, either the sender or the receiving end will have to make adaptions to the map so that it can be used within the portal. This amounts to a processing step converting a map following one ontology into one adhering another ontology. Depending on the complexity of such a transformation a query language may accomplish some of the tasks herein.
Knowledge is more than content. With content it is commonly assumed that the interpretation thereof is mainly in the eye of the beholder, mostly a human. The emerging knowledge management market is based on the mantra that at least some part of the interpretation can be left to a machine (MUC, machine understandable content) [lassila02].
Let us assume a Topic Map based database containing information about animals. Looking for lions will hopefully return everything the database knows about this particular concept: names in other languages, references to web sites covering lions in more detail. The topic also will hopefully be be connected via associations to other concepts.
More specific questions like "when are lions dangerous?" are much more difficult to handle than querying for a topic head. The query processor will have to assume that the query should run "when are lions dangerous to humans?". Then it would have to consult the topic map to find possible connections between the concept of danger, human and lion. If there is no direct relationship between these, then a query processor could use the information that "lions eat mammals when hungry". If they can further defer that a human is a mammal then they might give a reasonable answer.
A query language may support or at least facilitate queries like this if the engine is capable of inferencing, i.e. of making logical (or even heuristic) conclusions about stored facts.
The technical challenge, though, is that most useful application domains have an infinite or, at least a very high number of possible deductions. As such it is not feasible to store all possible consequences of all the given facts in a database. Consequently, the database will have to contain the given facts and the axioms. The query processor will then have to be capable to compute a deduction on request.
Businesses nowadays have a complex asset structure which they sometimes have to communicate to business partners, potential investors or - partially - to their customers. One technical option they have is to represent this knowledge about their assets in a topic map. Such map could contain use the organisational structure as backbone and could include a - more or less - high-level description of the products and services the company offers.
The (intangible) assets can be manifold: they can be patents associated with the key personel, the products, markets and courts the patent is or is planned to be leveraged. Assets also are the expertise of employees and business partners. Assets also can be further ideas which may be associated with people, markets and products. And assets also can include documentation about business processes and knowledge about business partners.
A Topic Map query language may help to analyze a current situation or make statements about possible scenarios. One example is a query which could ask which employees or associated business partners have an expertise in a particular area or market. In practical situations this will not be a precise query as the field of expertise is huge.
If we assume that a proposed project is described via a topic map, then a query might try to figure out which parts of the projects can be covered in-house and which other parts will have to be outsourced as there is no local expertise.
In this section we single out particular applications. This allows us to be more specific about how a TM query language can support the application engineer. Again, the applications described here have been chosen for variety and not for any commonalities they might share.
The photo meta-data database has become a canonical example in the meta data community and has already been prototypically implemented as [RDFWeb]. It serves as an experimental test case for the use of semantic web/ technologies.
The database contains information about depictions (photos), such as whether a particular one depicts a person or a landscape. Other meta information may be the date of creation or the person who actually made the picture.
An ontology for this application would maybe contain different classes of pictures and archival data about individual pictures such as sizes or the resolution. To capture the contents of pictures we will make heavy use of associations of type 'depicts' which connects a particular picture with the theme it depicts. To keep things manageable, we restrict ourselves to people, locations and capture everything else with a class 'thing' where we simply add keywords or free text for a description. Adopting [WordNet] as a namespace we might add URNs for those subjects where WordNet holds an entry.
A typical query would ask for all persons who were sitting in a bar. The TMQL query would have to use the above 'depicts' association type and would have to identify these pictures, which have both such a relationship, to a person and a thing which is a bar. The result of this query simply is a table which can be readily processed further.
Another query might try to find a thumbnail picture of a particular landscape. As it is unlikely that a picture with arbitrarily given dimensions will exist in the database, a best match will have to be found.
The easiest way to achieve this, is to retrieve all images and sort them according to the dimension (either the length, the height or both). A cutoff condition takes care that only images below a particular size are returned.
A third, more sophisticated query might involve not conditions on single pictures, but on the database on the whole. Given particular persons Q0 and Qn we could ask which images either depict both, or otherwise which pictures contain other persons Q1, Q2, ... such that Q0 and Q1 are on one picture, Q1 and Q2 are, so are Q2 and Q3 and finally Qn-1 and Qn. Such chains of depiction could indicate so connections between individuals.
Visualisation of Topic Map based data will be a much sought-after feature for applications. Due to the limited space on a screen the visualising process must filter away information from potentially rich topic maps. Which information to show to which user in which context may also depend on the application: Information not shown to a user may be perceived as non-existing or even be misinterpreted as wrong.
Applications therefore will need a rather flexible way to create a number of these filter. The application developer should not be forced to rewrite the extraction of data from a topic map over and over again. Instead they will build a query statement according to the current scenario. The query statement will include not only a way to identify the relevant parts within a map, but also will return only the requested information. Such will also help to reduce clutter and traffic if such an exchange occurs over a network.
As an example we consider a topic map containing information about albums, tracks, artists and such. If we were to convert this information into [SVG] we might adopt either a generic or an application specific approach. According to the former we would provide a set of queries which would simply accept a - given but variable - topic as focal node and which would extract all topics connected via associations. These other topics would then be placed around the focal node.
Another alternative would be to make use of the knowledge about the particular application domain. In that we define scenarios; they would define not only the (exact or approximate) position of nodes on the screen but also what kind of information they should carry and potentially also how they are rendered eventually. In our music example one such scenario could choose the 'album' - whatever it might be - to be the focal node. It would be shown as a rectangle containing the album head, maybe propped up with a small image of a disc. The artist always would be placed left with the name. If that is a group the icons would indicate such and would provide a pop-up function to look at the names of the group members. For individual artist, the artist's name directly appear right to the album, and so on.
Scenarios can so tightly control the amount of information for a particular class of users. Queries would be used to pull only this information from the map which is necessary to populate a given scenario. In our case this would be the basenames of the album, the artist(s) and that of other nodes in the scenario.
Whenever an application has to cope with a topic map with an unknown or unclear ontology, a TMQL may help to discover the structure and form of the map. This applies to Topic Map analysis tools for reengineering existing maps, to generic user interfaces using Topic Map data but also optimizing Topic Map data stores.
All of them have to detect structural aspects of a map, such as which topics are used as
classes in class-instance associations for topics, which are used as types of
occurrences and which are association types. Other queries might try to detect the type
hierarchy (taxonomy) which is used in a given map, others may want to analyse whether the
set of typing topics and the set of scoping topics is disjunct.
More sophisticated queries might try to figure which association types are used in associations between two (or more) particular topics. So, for instance, we might ask which kind of direct relationships exist between a topic 'Osama-Bin-Laden' and 'Twin-Towers'. This may be then used for Topic Map quality assurance. Similar queries would ask more general what kind of relationships exists between particular types of topics. To continue our zeitgeist example, we could ask for all association types which exist between any topic of type 'terrorist' and 'terror-attack'.
More topological queries could target any topic which is not used at all or may try to find a chain of associations between a set of given topics.
Part of the analysis will not only be qualitative but also quantitative: Statistics about the use of topics and the degree of connectivity of a map may facilitate quality management on a higher level. Queries would compute the number of topics, associations, and unconnected topic map parts.
[BibTeX] is a system to manage literature references as authors need when they reference other documents, usually within LaTeX documents. For this, BibTeX maintains the concept of a citation database, a text file which carries information about books, articles or other predefined classes of documents. Every such class has a set of mandatory attributes and also optional ones; a book might have an author or an editor, an article must have a header and one or more authors.
While convenient to use, the data model (and thus the underlying ontology) is biased to an individual user. Other uses were not directly anticipated. If, in contrast, an organisation stores literature information in a more flexible model - like one that Topic Maps provide - then this model might be rather oblivious of a particular use case. Authorship and editorship would of course be modelled as associations between the document and the author topic. So would publications as they connect documents with publishers.
In the following we detail particular queries against an assumed literature reference database described next.
Our test database contains information about literature references.
While the test data has a realistic background, it is not supposed to reflect reality.Ed. Note:
This test map is available in XTM and in AsTMa= format. The XTM version is generated from the AsTMa= version.
For reference, the following illustrations give an overview over the data and the associations used.
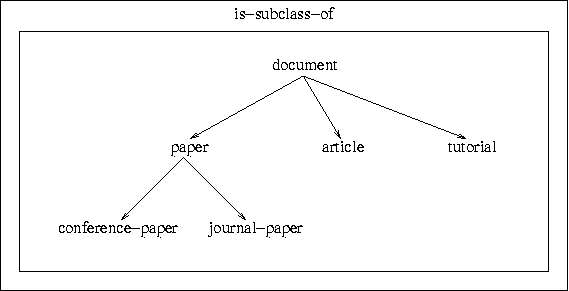
|
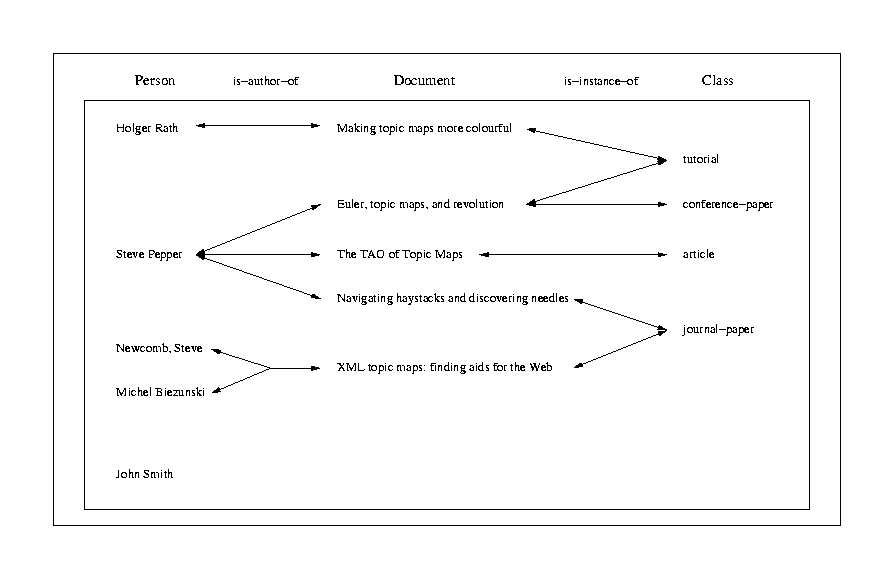
|
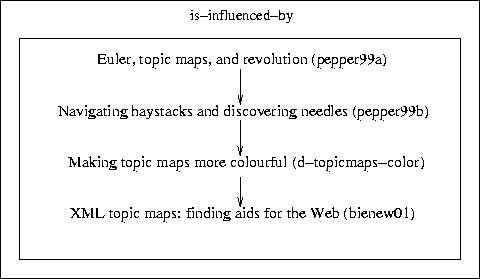
|
We will use the following assumptions and conventions:
There exists a topic with an identifier unconstrained-scope which
represents the unconstrained scope.
It is assumed that subclasses represents
http://www.topicmaps.org/xtm/1.0/core.xtm#superclass-subclass,
superclass represents
http://www.topicmaps.org/xtm/1.0/core.xtm#superclass and
subclass represents
http://www.topicmaps.org/xtm/1.0/core.xtm#subclass.
This association type should have the implicit property that if a is an
instance of A and A is a subclass of B then
a is also an instance of B. The binary relation
subclasses is to be interpreted non-reflexive and transitive.
Furthermore we assume that de and en are both
representations of the corresponding languages german and
english.
We refer to the basename value of a person topic as the persons's
name; the basename value in the scope sort we call the
sort name. The person's email address is the value of an
occurrence of type email. In a similar way we refer to the basename of
a document topic as the title of the document. The
publication date, language, abstract and the
download URL are all occurrence values of of occurrence items for a
document topics, typed accordingly.
An author is simply a person which has a is-author-of
association with a topic of class document. Conversely, a
publication is a document which has been authored by someone.
This category of queries returns lists as results. In this respect the language will behave like SQL in that it can also return (sometimes ordered) lists of tuples. The tuples themselves may contain items such as simple strings, text generated from the topic maps, topic ids, numbers but also information items as defined by [TMDM].
It is left open how a language framework covers the concept of list output. A framework may use a dedicated list type or may even map this into a different data model, such as that provided by XML DOM or Topic Maps themselves.
For every query we list the expected results. The order of the sample output is irrelevant unless a specific ordering is explicitely requested in the query.
In the case that strings are to be returned as part of a tuple, we will directly list them in the sample outputs below whereby we do not distinguish between string and numerical data.
We cannot denote values in the case TMDM information items are to be returned; here we
will use an ad-hoc syntax: [ some-topic-id ] represents the topic item of
the topic addressed by the topic identifier some-topic-id, [
"basename string", some-scope ] stands for a base name item with the given string
and scope (the other properties remain undefined here), [ occurrence-type,
"occurrence value", occurrence-scope ] accordingly for an occurrence item with
the given type, value and scope (other properties remain undefined).
Ed. Note:
CXTM would be a candidate.
We also make use of topic identifiers to identify topics and to characterize the output. Implementations are supposed to provide a unique identification of topics, be it only via subject identifiers or via topic identifiers. The latters may be only valid locally to a map and/or local to a session.
Some queries may not be directly implementable by a proposal. For these, the use case should elicit suggestions how the language intends to use extensions to solve this problem.
Ed. Note:
In the following, sample queries ask for Topic Map content sometimes in form of string values, sometimes of information items. This choices have been rather arbitrary; language designers should consider both options for all these queries. For reasons of presentation most queries use text output, though, and only some explicitely ask for information items.
Retrieve all author names, i.e. the name of a topic which plays the role author in an is-author-of association.
"Holger Rath" "Michel Biezunski" "Steve Pepper" "Steve Newcomb"
Retrieve the name of all authors, this time ordered by the sort name provided in person topics.
"Michel Biezunski" "Steve Newcomb" "Steve Pepper" "Holger Rath"
Retrieve the titles of all tutorials. The titles should be preferably those in scope en, de or in the unconstrained scope, in that order.
"Making topic maps more colourful" "Euler, Topic Maps und Revolution"
Retrieve the names of all persons who have not authored anything.
"John Smith"
Retrieve a list of all author names together with the title of their publications.
"Holger Rath", "Making topic maps more colourful" "Steve Pepper", "Euler, topic maps, and revolution" "Steve Pepper", "Navigating haystacks and discovering needles" "Steve Pepper", "The TAO of Topic Maps" "Steve Newcomb", "XML topic maps: finding aids for the Web" "Michel Biezunski", "XML topic maps: finding aids for the Web"
Retrieve a list of all titles of documents which are tutorials (i.e. are a direct or indirect instance of class tutorial) sorted by publication date, descending.
"Making topic maps more colourful", 2000 "Euler, topic maps, and revolution", 1999
Retrieve a list of documents, sorted by publication date (ascending), only number 3 to 5, inclusive, together with this order number.
3,"The TAO of Topic Maps", 2000 4,"Making topic maps more colourful", 2000 5,"XML topic maps: finding aids for the Web", 2001
Retrieve all topic identifiers of documents which have a download URL.
pepper99a pepp00 d-topicmaps-color
Retrieve a list of author's email addresses where the author has authored documents for which no download URL exists. Include the topic identifiers of these documents.
pepper@n0spam.ontopia.net, pepper99b srn@n0spam.coolheads.com, bienew01 mb@n0spam.coolheads.com, bienew01
Retrieve a list of author names where the author has written more than 1 document.
"Steve Pepper"
A list of author names where the author has not written a single document with someone else. As the person must be an author, she must have written at least one document.
"Steve Pepper" "Holger Rath"
Retrieve all topic identifiers of documents and their URLs which have a non-working URL at query time.
pepp00, http://www.broken.example.com/
Retrieve all topic identifiers for documents for which the abstract in english (i.e. the occurrence of type abstract in scope en) contains the phrase 'topic map' or 'topic maps', case-insensitive.
pepp00 bienew01
Retrieve all documents which have a title in german (i.e. a basename in the scope de).
[ empty list ]
Retrieve all topic identifiers of the pairs of documents which share at least one word in the title, ignoring stopwords like 'and', 'of', 'the'. No duplicates in this list are allowed. Note: Duplicates of the form (a, b) and (b, a) may be allowed. The result should be sorted by the identifiers.
d-topicmaps-color, bienew01 pepp00, bienew01 pepp00, d-topicmaps-color pepper99a, bienew01 pepper99a, d-topicmaps-color pepper99a, pepp00
Retrieve the identifiers of all topics which represent information resources on the ontopia.net server(s).
pepper99a pepp00
Retrieve the topic identifiers of all documents which are not written in the language English (or where there is no information about that), i.e. where there is no occurrence of type language.
pepper99b pepp00 d-topicmaps-color
Retrieve the topic identifiers of all documents which are directly or indirectly influenced by something which Steve Pepper wrote (i.e. interpreting "influenced by" as non-reflexive, but transitive relation). Copy the topic identifiers of the influential papers to the output.
pepper99b, 'influenced by', pepper99a d-topicmaps-color, 'influenced by', pepper99b d-topicmaps-color, 'influenced by', pepper99a bienew01, 'influenced by', pepper99b bienew01, 'influenced by', pepper99a
Retrieve all identifiers of topics which are either (direct or indirect) instances of paper or tutorial. Duplicates should be suppressed.
pepper99a pepper99b d-topicmaps-color bienew01
Retrieve all titles of all publications (regardless their scope) together with their most specific class, i.e. that class where this publication is directly (and not indirectly) an instance of.
Euler, topic maps, and revolution, conference-paper Euler, topic maps, and revolution, tutorial Euler, Topic Maps und Revolution, conference-paper Euler, Topic Maps und Revolution, tutorial Navigating haystacks and discovering needles, journal-paper The TAO of Topic Maps, article Making topic maps more colourful, tutorial XML topic maps: finding aids for the Web, journal-paper
Retrieve all authors (i.e. all topic items which play the role author in an is-author-of association).
[ holger-rath ] [ michel-biezunski ] [ steve-pepper ] [ steve-newcomb ]
Retrieve all basename items of topics which play the role author in an is-author-of association).
[ "Holger Rath", unconstrained-scope ] [ "Michel Biezunski", unconstrained-scope ] [ "Steve Pepper", unconstrained-scope ] [ "Steve Newcomb", unconstrained-scope ]
Retrieve a list of all occurrence items being of type email.
[ email, srn@n0spam.coolheads.com, unconstrained-scope ] [ email, mb@n0spam.coolheads.com, unconstrained-scope ] [ email, pepper@n0spam.ontopia.net, unconstrained-scope ] [ email, holger.rath@n0spam.empolis.com, unconstrained-scope ] [ email, j.smith@example.com, unconstrained-scope ]
This section contains queries which result in XML instances which are handed to the application. These instances are either complete XML documents or may also be fragments of XML data.
To characterize the result we provide the (serialized) XML response. Unless specified explicitely, any number of white-spaces can appear within elements with no text content. For clarification we also append the DTD of these responses. Individual proposals may or may not use them as additional input to a query.
Unless specified explicitely, no particular ordering is prescribed.
Return all titles of papers (conference papers, journal papers) together with the author names. The use of white-spaces should be exactly as depicted.
<papers>
<paper>
<head>Euler, topic maps, and revolution</head>
<author>Steve Pepper</author>
</paper>
<paper>
<head>Navigating haystacks and discovering needles</head>
<author>Steve Pepper</author>
</paper>
<paper>
<head>XML topic maps: finding aids for the Web</head>
<author>Steve Newcomb</author>
<author>Michel Biezunski</author>
</paper>
</papers>
whereby the XML document should adhere to the following DTD:
<!ELEMENT papers (paper*)> <!ELEMENT paper (head, author*)> <!ELEMENT head (#PCDATA)> <!ELEMENT author (#PCDATA)>
Return the name(s) of all authors who have authored more than one paper.
The result should look like this:
<recidivists> <author>Steve Pepper</author> </recidivists>whereby the XML document should adhere to the following DTD:
<!ELEMENT recidivists (author*)> <!ELEMENT author (#PCDATA)>
Select only the tutorial documents from the topic map and return an RDF document containing the title and the author information.
The result should look like this:
<rdf:RDF xmlns:rdf="http://www.w3c.org/RDF/"
xmlns:lit="http://www.isotopicmaps.org/tmql/use-cases/literature/">
<lit:tutorial rdf:about="http://www.ontopia.net/topicmaps/materials/euler.pdf">
<lit:title>Euler, topic maps, and revolution</lit:title>
<lit:author>Steve Pepper</lit:author>
</lit:tutorial>
<lit:tutorial rdf:about="http://www.gca.org/papers/xmleurope2000/papers/s29-01.html">
<lit:title>Making topic maps more colourful</lit:title>
<lit:author>Holger Rath</lit:author>
</lit:tutorial>
</rdf:RDF>
Return all persons with their name and a bibliography as nested elements. The bibliography should contain a list of publications with title and language - if available - in brackets (if unavailable, the text "unknown" should be inserted). This list should be sorted by the publication date in descending order.
All person elements must contain an ID attribute holding the respective
topic identifier of the person's topic.
The result should look like this:
<persons>
<person id="john-smith">
<name>Smith, John </name>
<bibliography>unknown</bibliography>
</person>
<person id="holger-rath">
<name>Rath, Holger</name>
<bibliography>
<publication>Making topic maps more colourful (unknown)</publication>
</bibliography>
</person>
<person id="steve-pepper">
<name>Pepper, Steve</name>
<bibliography>
<publication>The TAO of Topic Maps (unknown)</publication>
<publication>Navigating haystacks and discovering needles (unknown)</publication>
<publication>Euler, topic maps, and revolution (english)</publication>
</bibliography>
</person>
<person id="michel-biezunski">
<name>Biezunski, Michel</name>
<bibliography>
<publication>XML topic maps: finding aids for the Web (english)</publication>
</bibliography>
</person>
<person id="steve-newcomb">
<name>Newcomb, Steve</name>
<bibliography>
<publication>XML topic maps: finding aids for the Web (english)</publication>
</bibliography>
</person>
</persons>
whereby the XML document should adhere to the following DTD:
<!ELEMENT persons (person*)> <!ELEMENT person (name bibliography)> <!ATTLIST person id ID #REQUIRED> <!ELEMENT name (#PCDATA)> <!ELEMENT bibliography (publication*)> <!ELEMENT publication (#PCDATA)> <!ATTLIST publication id ID #REQUIRED>
This section contains queries which return an instance of a topic map. It is left open whether the map should be represented only textually (in some Topic Map notation) or is represented in a TMDM-conformant manner. It is also left open whether the map is in itself complete in the sense that all topics used are actually present in the map.
Create a topic map according to the following specification:
publication-date with associations of
type was-published-in. For the daterole the topic players
should use ids of the form x-dates-yyyy.The returned result should be equivalent with a deserialized form of the following map:
Ed. Note:
This map is available in XTM and in AsTMa= format. The XTM version is derived automatically from the AsTMa= version.
Create a topic map according to the following specification:
publication. All other documents
should be of class no-publication.
is-published-by where
the document plays the role document and
the topic prints-are-us plays the
publisher. If the document has a
publication date, then an additional role
date should be added. The topic playing this role should
represent the date via a URI of the form urn:x-date:yyyy.
The returned result should be equivalent with a deserialized form of the following map:
Ed. Note:
This map is available in XTM and in AsTMa= format. The XTM version is derived automatically from the AsTMa= version.
Apart from the queries in the previous section which address information on a topic map level, many applications will need to retrieve directly Topic Map information items as described in [TMDM].
It is to be expected that these queries will be rather frequent, especially in a web environment. For the language designer this could mean that it should be simple to express these queries; for the implementer a large amount of these queries may put some stress on any Topic Map store.
The following queries have been collected from [schmidt01], [Wrightson00] and [Ksiezyk00].
Ed. Note:
These queries and their similarity relationship is also available in XTM and in AsTMa= format. The XTM version is generated from the AsTMa= version.
In this draft the editors tried to consolidate considerable work done before in this area by others, specifically on the TMQL mailing list. The use cases were collected from various sites, among them the Ontopia site and the Techquila sites. Special thanks to Ann Wrightson and Erica Santosaputri for contributing use cases.
Ed. Note:
The references are (of course) available in XTM and in AsTMa= format. The XTM version is generated from the AsTMa= version.